
Understanding and predicting motion is a fundamental component of visual intelligence. Although modern video models exhibit strong comprehension of scene dynamics, exploring multiple possible futures through full video synthesis remains prohibitively inefficient. We model scene dynamics orders of magnitude more efficiently by directly operating on a long-term motion embedding that is learned from large-scale trajectories obtained from tracker models. This enables efficient generation of long, realistic motions that fulfill goals specified via text prompts or spatial pokes. To achieve this, we...
Read the full story on the original source for primary detail and technical specifications.
Based on social velocity, sharing rate, and discussion volume across communities.
Estimated significance to the industry, potential for disruption, and technical novelty.
Automated Summarization
This content was automatically aggregated and summarized from Apple Machine Learning. Original content and nuance may vary.
Start the conversation.

The latest tools from Google can help you plan trips, find a great deal and explore your next destination.

Nano Banana 2 now uses your personal context and Google Photos to create images that reflect your unique life.
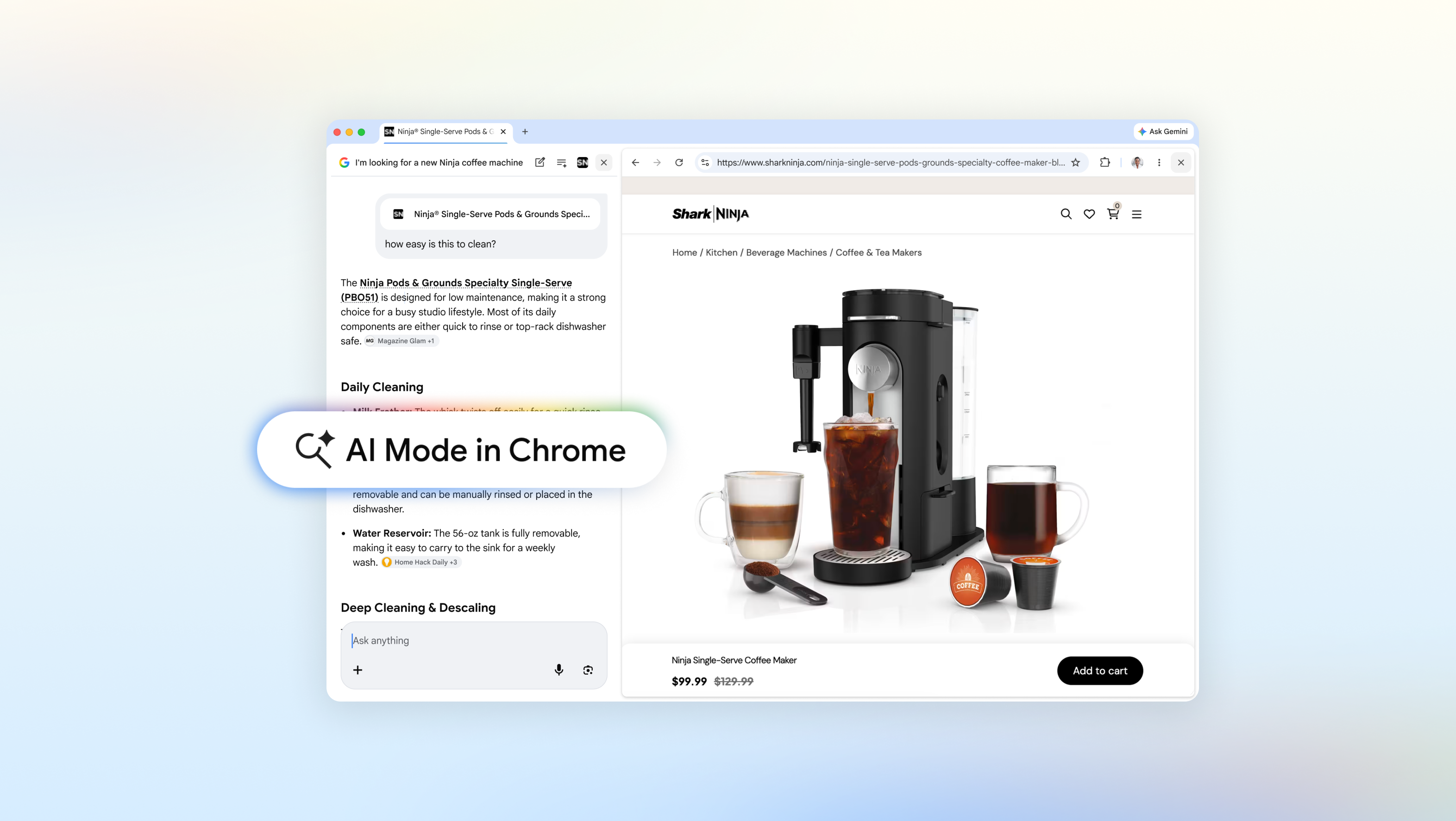
Today’s upgrades for AI Mode in Chrome transform how you interact with the web